
Choosing A Router In React Apps
Learn about the 4 types of routers in React, and understand which one you should use.


Most of us just install react-router and use the BrowserRouter. But, have you ever stopped and wondered why BrowserRouter is called BrowserRouter and not just Router? This indicates that there are different types of routers offered by react-router.
In this article, we’ll learn about these types, understand how to use them and finally, compare them to decide which one is best for your needs.
BrowserRouter
Uses everything after the domain(eg .com, .in, .io etc) as the path. For example, if the url is localhost:3000/home, then /home is the path/route. This router uses the HTML 5 History API to keep the UI in sync with the the path.
BrowserRouter is used for doing client side routing with URL segments. You can load a top level component for each route. This helps separate concerns in your app and makes the logic/data flow more clear. Let’s see how this can be implemented in code using react-router:
import { BrowserRouter, Route } from 'react-router-dom';
function App() {
return (
<BrowserRouter>
<Route path="/home" exact component={Home} />
</BrowserRouter>
);
}
We’ll look at the advantages and disadvantages when we compare the routers later.
HashRouter
This is similar (visually) to the browser router, with the only difference being that a # is added between the domain and the path. Let’s say the url is localhost:3000/#/home, then the /home is the route. Basically, it uses everything after the # as the path. Now, we’ll see how to implement this:
import { HashRouter, Route } from 'react-router-dom';
function App() {
return (
<HashRouter>
<Route path="/home" exact component={Home} />
</HashRouter>
);
}
We have an App() component in which we are returning a HashRouter with a route. If you run our little app in the browser, you will find out that react router automatically adds a # before the path.
That’s pretty much it. This is the main visual difference between a browser router and a hash router. The # does not seem very relevant but trust me, it has a perfectly valid reason.
Important Note: location.state and location.key does not work with react-router’s HashRouter.
MemoryRouter
It keeps the history of your “URL” in memory (does not read or write to the address bar). It’s useful in tests and non-browser environments like React Native.
import { MemoryRouter, Route } from 'react-router';
function App() {
return (
<MemoryRouter>
<Route path="/home" exact component={Home} />
</MemoryRouter>
);
}
The component will change when you click on a link but the url will remain the same
StaticRouter
This is useful in server-side rendering scenarios when the user isn’t actually clicking around, so the location never actually changes. Hence, the name: static. It’s also useful in simple tests when you just need to plug in a location and make assertions on the render output.
Comparing Routers
1. Browser Router
The browser router is often very complicated to deploy to servers. It uses history API, so it’s unavailable for legacy browsers (IE 9... but who cares about that, it's almost 2022).
Client-side React application is able to maintain clean routes like example.com/react/route but needs to be backed by a web server. A traditional web server evaluates requests like this:
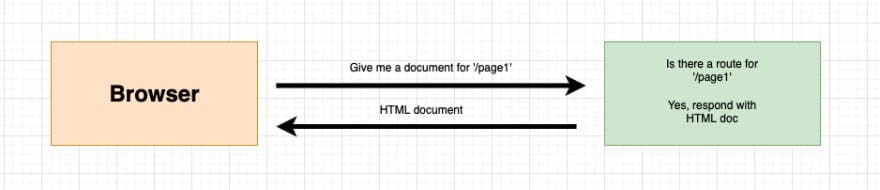
In case of a single page application, it’s just a single index.html file which requires some extra configuration on the hosting server.
However, these days a lot of hosting providers assume that we use this kind of routing and simplify the process.
We can also use server side rendering with this router, index.html may contain rendered components or data that are specific to current route.
2. Hash Router
Enough of browser routers, let’s talk hash routers. We can quite easily configure our server to ignore the # and server the entire html file regardless of the route. This hash will be used by our routes to show the appropriate content.
Also, HashRouter use cases aren't limited to SPA. A website may have legacy or search engine-friendly server-side routing, while React application may be a widget that maintains its state in URL like example.com/server/side/route#/react/route.
3. Memory Router
Memory routers will refresh/change the component but not the url. This probably will leave the user hanging and he or she might think that his computer has hanged or there is an issue with the site which is certainly not pleasant for the user.
On the other hand, this is great for environments in which the url is not shown like React Native, Testing Environments etc.
4. Static Router
Static routing can be used to define an exit point from a router when no other routes are available or necessary which is called a default route. Think of this as a fallback route(404s). Static routing can be used for small networks that require only one or two routes.
Conclusion
The router you pick largely depends on the application, amount of resources and deployment. Use browser routers if your hosting provider automatically does most of the configuration for you or you have the resources to hire a devOps guy. I’d recommend hash routers when you want to quickly deploy without any hassle.
Memory routers are helpful in test environments and react native. I added memory routers just for your information but I’m not a huge fan of it because I mainly work with browser environments, where it's not very useful.
That’s all for now, I hope you guys liked this post! Please, like this post if you learned something new. Follow me on twitter where I post tips and threads about web development. Bye for now 🤘